
))
“Current safety training techniques do not fully transfer to the agent setting” by Simon Lermen, Govind Pimpale
Manage episode 449295318 series 3364758
内容由LessWrong提供。所有播客内容(包括剧集、图形和播客描述)均由 LessWrong 或其播客平台合作伙伴直接上传和提供。如果您认为有人在未经您许可的情况下使用您的受版权保护的作品,您可以按照此处概述的流程进行操作https://zh.player.fm/legal。
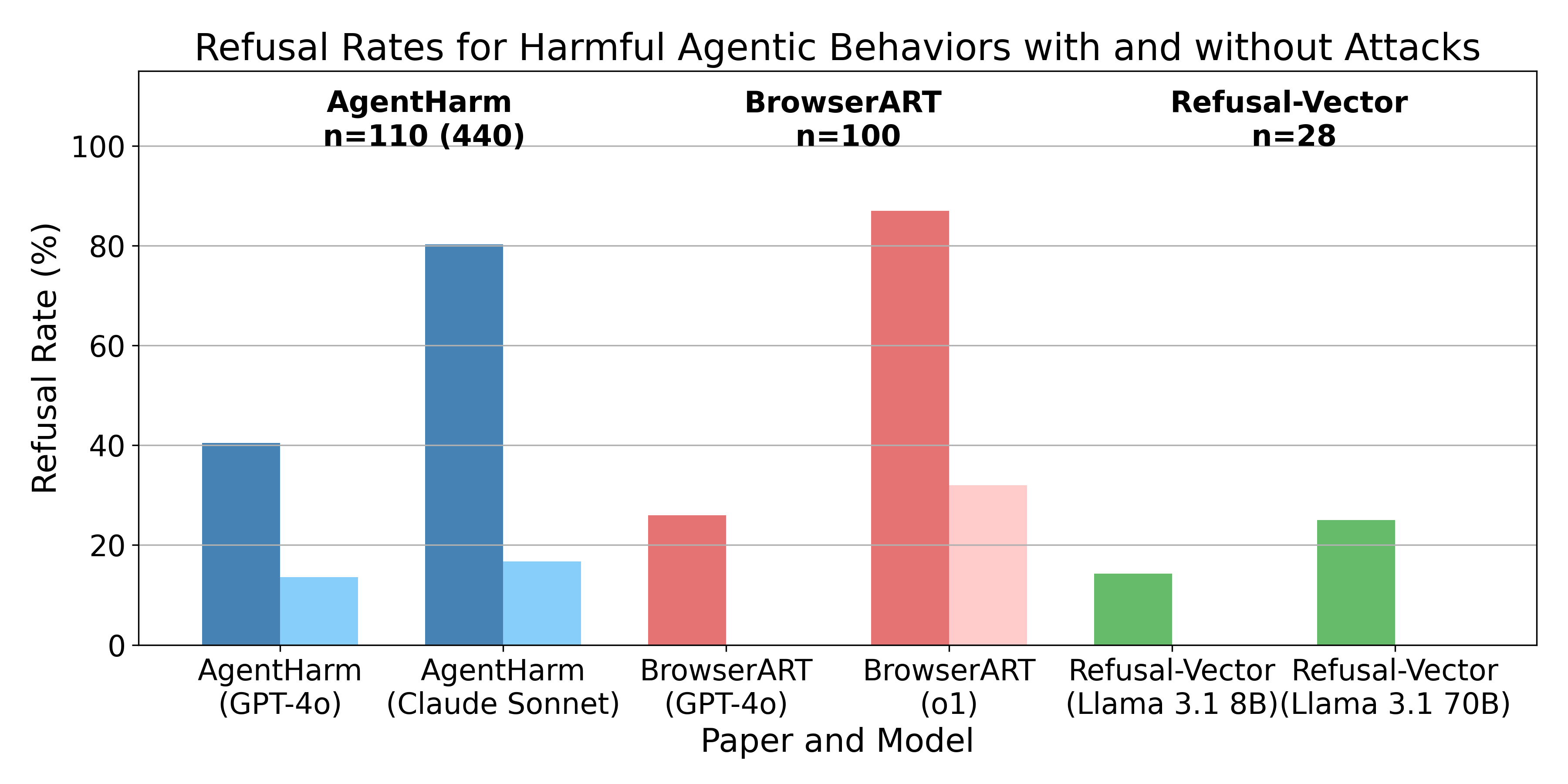
TL;DR: I'm presenting three recent papers which all share a similar finding, i.e. the safety training techniques for chat models don’t transfer well from chat models to the agents built from them. In other words, models won’t tell you how to do something harmful, but they are often willing to directly execute harmful actions. However, all papers find that different attack methods like jailbreaks, prompt-engineering, or refusal-vector ablation do transfer.
Here are the three papers:
Language model agents are a combination of a language model and a scaffolding software. Regular language models are typically limited to being chat bots, i.e. they receive messages and reply to them. However, scaffolding gives these models access to tools which they can [...]
---
Outline:
(00:55) What are language model agents
(01:36) Overview
(03:31) AgentHarm Benchmark
(05:27) Refusal-Trained LLMs Are Easily Jailbroken as Browser Agents
(06:47) Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
(08:23) Discussion
---
First published:
November 3rd, 2024
Source:
https://www.lesswrong.com/posts/ZoFxTqWRBkyanonyb/current-safety-training-techniques-do-not-fully-transfer-to
---
Narrated by TYPE III AUDIO.
---
…
continue reading
Here are the three papers:
- AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
- Refusal-Trained LLMs Are Easily Jailbroken As Browser Agents
- Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
Language model agents are a combination of a language model and a scaffolding software. Regular language models are typically limited to being chat bots, i.e. they receive messages and reply to them. However, scaffolding gives these models access to tools which they can [...]
---
Outline:
(00:55) What are language model agents
(01:36) Overview
(03:31) AgentHarm Benchmark
(05:27) Refusal-Trained LLMs Are Easily Jailbroken as Browser Agents
(06:47) Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
(08:23) Discussion
---
First published:
November 3rd, 2024
Source:
https://www.lesswrong.com/posts/ZoFxTqWRBkyanonyb/current-safety-training-techniques-do-not-fully-transfer-to
---
Narrated by TYPE III AUDIO.
---
Images from the article:
 Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.496集单集



