Best Business Podcast (Gold), British Podcast Awards 2023 How do you build a fully electric motorcycle with no compromises on performance? How can we truly experience what the virtual world feels like? What does it take to design the first commercially available flying car? And how do you build a lightsaber? These are some of the questions this podcast answers as we share the moments where digital transforms physical, and meet the brilliant minds behind some of the most innovative products a ...
…
continue reading
内容由O'Reilly Media提供。所有播客内容(包括剧集、图形和播客描述)均由 O'Reilly Media 或其播客平台合作伙伴直接上传和提供。如果您认为有人在未经您许可的情况下使用您的受版权保护的作品,您可以按照此处概述的流程进行操作https://zh.player.fm/legal。
类似 O'Reilly Data Show Podcast 的节目
Custom Manufacturing Industry podcast is an entrepreneurship and motivational podcast on all platforms, hosted by Aaron Clippinger. Being CEO of multiple companies including the signage industry and the software industry, Aaron has over 20 years of consulting and business management. His software has grown internationally and with over a billion dollars annually going through the software. Using his Accounting degree, Aaron will be talking about his organizational ways to get things done. Hi ...
…
continue reading
It didn’t all change in March 2020. Not really. The UK high street has been in the throes of a gradual revolution for decades. From the rise of ecommerce, to the birth of mobile, social commerce, and a growing emphasis on experience, change has been underway for a while. In fact for many, the pandemic has acted as a wake-up call. Digital transformation was no longer a ‘nice to have’ but a matter of survival. Necessity sparked innovation and customers are enjoying more flexibility and conveni ...
…
continue reading
Hosts Isaac Butler, Ronald Young Jr., and June Thomas interview creative people about how they write, compose, paint, and more.
…
continue reading
The Partnership Economy explores the power of partnerships through candid conversations and stories with industry leaders. Our hosts, David A. Yovanno, CEO and Todd Crawford, Co-founder, of impact.com, unpack the future of partnerships as a lever for scale and an opportunity to put the consumer first.
…
continue reading
Flash Forward is a show about possible (and not so possible) future scenarios. What would the warranty on a sex robot look like? How would diplomacy work if we couldn’t lie? Could there ever be a fecal transplant black market? (Complicated, it wouldn’t, and yes, respectively, in case you’re curious.) Hosted and produced by award winning science journalist Rose Eveleth, each episode combines audio drama and journalism to go deep on potential tomorrows, and uncovers what those futures might re ...
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
Alessandro Bogliari, CEO and Co-Founder of The Influencer Marketing Factory, a global influencer marketing agency, talks with great guests about influencer marketing, social media, the creator economy, social commerce and much more.
…
continue reading
As She Rises brings together local poets and activists from throughout North America to depict the effects of climate change on their home and their people. Each episode carries the listener to a new place through a collection of voices, local recordings and soundscapes. Stories span from the Louisiana Bayou, to the tundras of Alaska to the drying bed of the Colorado River. Centering the voices of native women and women of color, As She Rises personalizes the elusive magnitude of climate cha ...
…
continue reading
Wharton faculty and industry leaders discuss their latest research, books, and relevant business topics. Hosted on Acast. See acast.com/privacy for more information.
…
continue reading
Player FM -播客应用
使用Player FM应用程序离线!
使用Player FM应用程序离线!

))
Labeling, transforming, and structuring training data sets for machine learning
Manage episode 248276630 series 61203
内容由O'Reilly Media提供。所有播客内容(包括剧集、图形和播客描述)均由 O'Reilly Media 或其播客平台合作伙伴直接上传和提供。如果您认为有人在未经您许可的情况下使用您的受版权保护的作品,您可以按照此处概述的流程进行操作https://zh.player.fm/legal。
In this episode of the Data Show, I speak with Alex Ratner, project lead for Stanford’s Snorkel open source project; Ratner also recently garnered a faculty position at the University of Washington and is currently working on a company supporting and extending the Snorkel project. Snorkel is a framework for building and managing training data. Based on our survey from earlier this year, labeled data remains a key bottleneck for organizations building machine learning applications and services.
Ratner was a guest on the podcast a little over two years ago when Snorkel was a relatively new project. Since then, Snorkel has added more features, expanded into computer vision use cases, and now boasts many users, including Google, Intel, IBM, and other organizations. Along with his thesis advisor professor Chris Ré of Stanford, Ratner and his collaborators have long championed the importance of building tools aimed squarely at helping teams build and manage training data. With today’s release of Snorkel version 0.9, we are a step closer to having a framework that enables the programmatic creation of training data sets.
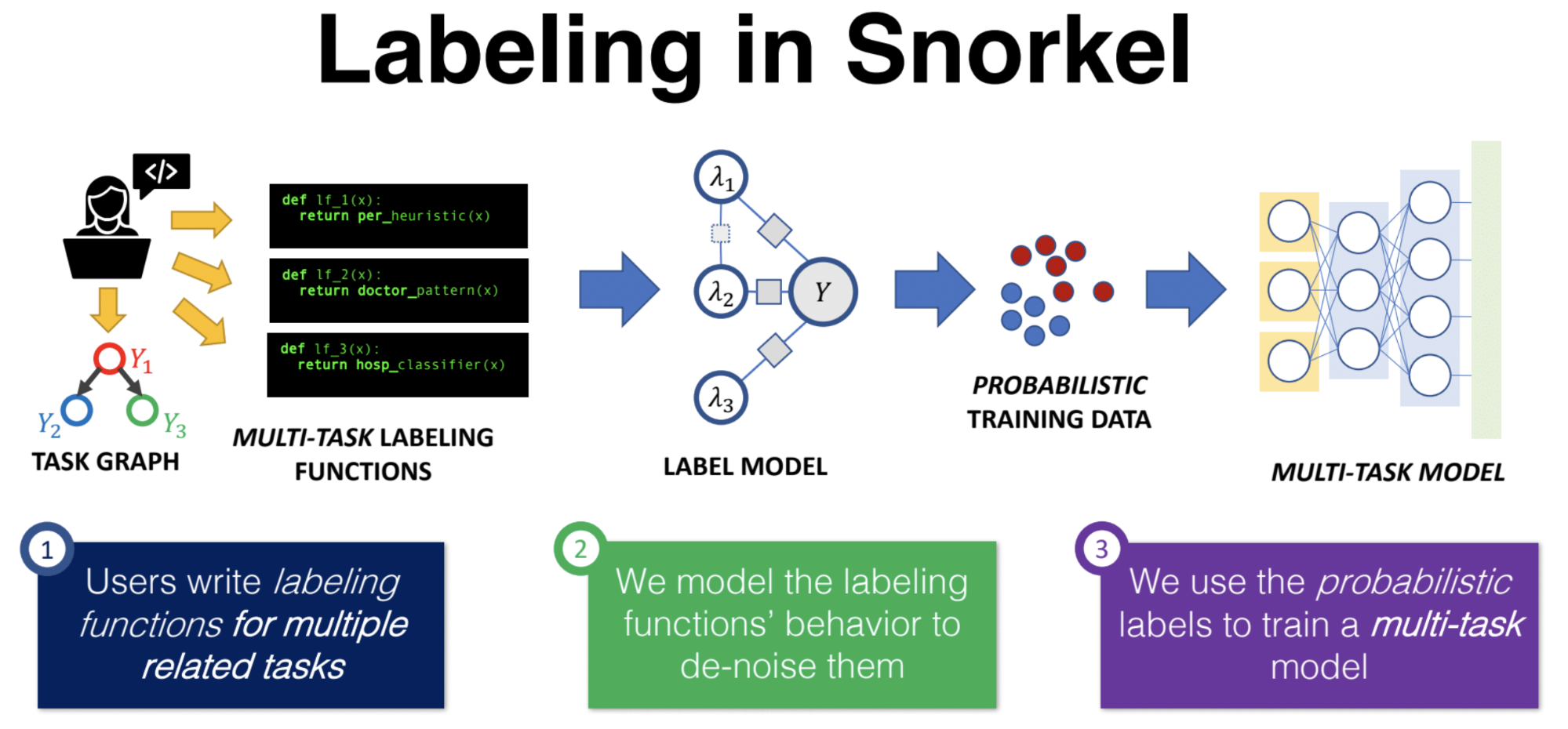
We had a great conversation spanning many topics, including:
- Why he and his collaborators decided to focus on “data programming” and tools for building and managing training data.
- A tour through Snorkel, including its target users and key components.
- What’s in the newly released version (v 0.9) of Snorkel.
- The number of Snorkel’s users has grown quite a bit since we last spoke, so we went through some of the common use cases for the project.
- Data lineage, AutoML, and end-to-end automation of machine learning pipelines.
- Holoclean and other projects focused on data quality and data programming.
- The need for tools that can ease the transition from raw data to derived data (e.g., entities), insights, and even knowledge.
Related resources:
- “Product management in the machine learning era”: A tutorial at the Artificial Intelligence Conference in San Jose, September 9-12, 2019.
- Chris Ré: “Software 2.0 and Snorkel”
- Alex Ratner: “Creating large training data sets quickly”
- Ihab Ilyas and Ben Lorica on “The quest for high-quality data”
- Roger Chen: “Acquiring and sharing high-quality data”
- Jeff Jonas on “Real-time entity resolution made accessible”
- “Data collection and data markets in the age of privacy and machine learning”
168集单集
Manage episode 248276630 series 61203
内容由O'Reilly Media提供。所有播客内容(包括剧集、图形和播客描述)均由 O'Reilly Media 或其播客平台合作伙伴直接上传和提供。如果您认为有人在未经您许可的情况下使用您的受版权保护的作品,您可以按照此处概述的流程进行操作https://zh.player.fm/legal。
In this episode of the Data Show, I speak with Alex Ratner, project lead for Stanford’s Snorkel open source project; Ratner also recently garnered a faculty position at the University of Washington and is currently working on a company supporting and extending the Snorkel project. Snorkel is a framework for building and managing training data. Based on our survey from earlier this year, labeled data remains a key bottleneck for organizations building machine learning applications and services.
Ratner was a guest on the podcast a little over two years ago when Snorkel was a relatively new project. Since then, Snorkel has added more features, expanded into computer vision use cases, and now boasts many users, including Google, Intel, IBM, and other organizations. Along with his thesis advisor professor Chris Ré of Stanford, Ratner and his collaborators have long championed the importance of building tools aimed squarely at helping teams build and manage training data. With today’s release of Snorkel version 0.9, we are a step closer to having a framework that enables the programmatic creation of training data sets.
We had a great conversation spanning many topics, including:
- Why he and his collaborators decided to focus on “data programming” and tools for building and managing training data.
- A tour through Snorkel, including its target users and key components.
- What’s in the newly released version (v 0.9) of Snorkel.
- The number of Snorkel’s users has grown quite a bit since we last spoke, so we went through some of the common use cases for the project.
- Data lineage, AutoML, and end-to-end automation of machine learning pipelines.
- Holoclean and other projects focused on data quality and data programming.
- The need for tools that can ease the transition from raw data to derived data (e.g., entities), insights, and even knowledge.
Related resources:
- “Product management in the machine learning era”: A tutorial at the Artificial Intelligence Conference in San Jose, September 9-12, 2019.
- Chris Ré: “Software 2.0 and Snorkel”
- Alex Ratner: “Creating large training data sets quickly”
- Ihab Ilyas and Ben Lorica on “The quest for high-quality data”
- Roger Chen: “Acquiring and sharing high-quality data”
- Jeff Jonas on “Real-time entity resolution made accessible”
- “Data collection and data markets in the age of privacy and machine learning”
168集单集
所有剧集
×欢迎使用Player FM
Player FM正在网上搜索高质量的播客,以便您现在享受。它是最好的播客应用程序,适用于安卓、iPhone和网络。注册以跨设备同步订阅。
类似 O'Reilly Data Show Podcast 的节目
Best Business Podcast (Gold), British Podcast Awards 2023 How do you build a fully electric motorcycle with no compromises on performance? How can we truly experience what the virtual world feels like? What does it take to design the first commercially available flying car? And how do you build a lightsaber? These are some of the questions this podcast answers as we share the moments where digital transforms physical, and meet the brilliant minds behind some of the most innovative products a ...
…
continue reading
Custom Manufacturing Industry podcast is an entrepreneurship and motivational podcast on all platforms, hosted by Aaron Clippinger. Being CEO of multiple companies including the signage industry and the software industry, Aaron has over 20 years of consulting and business management. His software has grown internationally and with over a billion dollars annually going through the software. Using his Accounting degree, Aaron will be talking about his organizational ways to get things done. Hi ...
…
continue reading
It didn’t all change in March 2020. Not really. The UK high street has been in the throes of a gradual revolution for decades. From the rise of ecommerce, to the birth of mobile, social commerce, and a growing emphasis on experience, change has been underway for a while. In fact for many, the pandemic has acted as a wake-up call. Digital transformation was no longer a ‘nice to have’ but a matter of survival. Necessity sparked innovation and customers are enjoying more flexibility and conveni ...
…
continue reading
Hosts Isaac Butler, Ronald Young Jr., and June Thomas interview creative people about how they write, compose, paint, and more.
…
continue reading
The Partnership Economy explores the power of partnerships through candid conversations and stories with industry leaders. Our hosts, David A. Yovanno, CEO and Todd Crawford, Co-founder, of impact.com, unpack the future of partnerships as a lever for scale and an opportunity to put the consumer first.
…
continue reading
Flash Forward is a show about possible (and not so possible) future scenarios. What would the warranty on a sex robot look like? How would diplomacy work if we couldn’t lie? Could there ever be a fecal transplant black market? (Complicated, it wouldn’t, and yes, respectively, in case you’re curious.) Hosted and produced by award winning science journalist Rose Eveleth, each episode combines audio drama and journalism to go deep on potential tomorrows, and uncovers what those futures might re ...
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
Alessandro Bogliari, CEO and Co-Founder of The Influencer Marketing Factory, a global influencer marketing agency, talks with great guests about influencer marketing, social media, the creator economy, social commerce and much more.
…
continue reading
As She Rises brings together local poets and activists from throughout North America to depict the effects of climate change on their home and their people. Each episode carries the listener to a new place through a collection of voices, local recordings and soundscapes. Stories span from the Louisiana Bayou, to the tundras of Alaska to the drying bed of the Colorado River. Centering the voices of native women and women of color, As She Rises personalizes the elusive magnitude of climate cha ...
…
continue reading
Wharton faculty and industry leaders discuss their latest research, books, and relevant business topics. Hosted on Acast. See acast.com/privacy for more information.
…
continue reading
Player FM -播客应用
使用Player FM应用程序离线!
使用Player FM应用程序离线!



